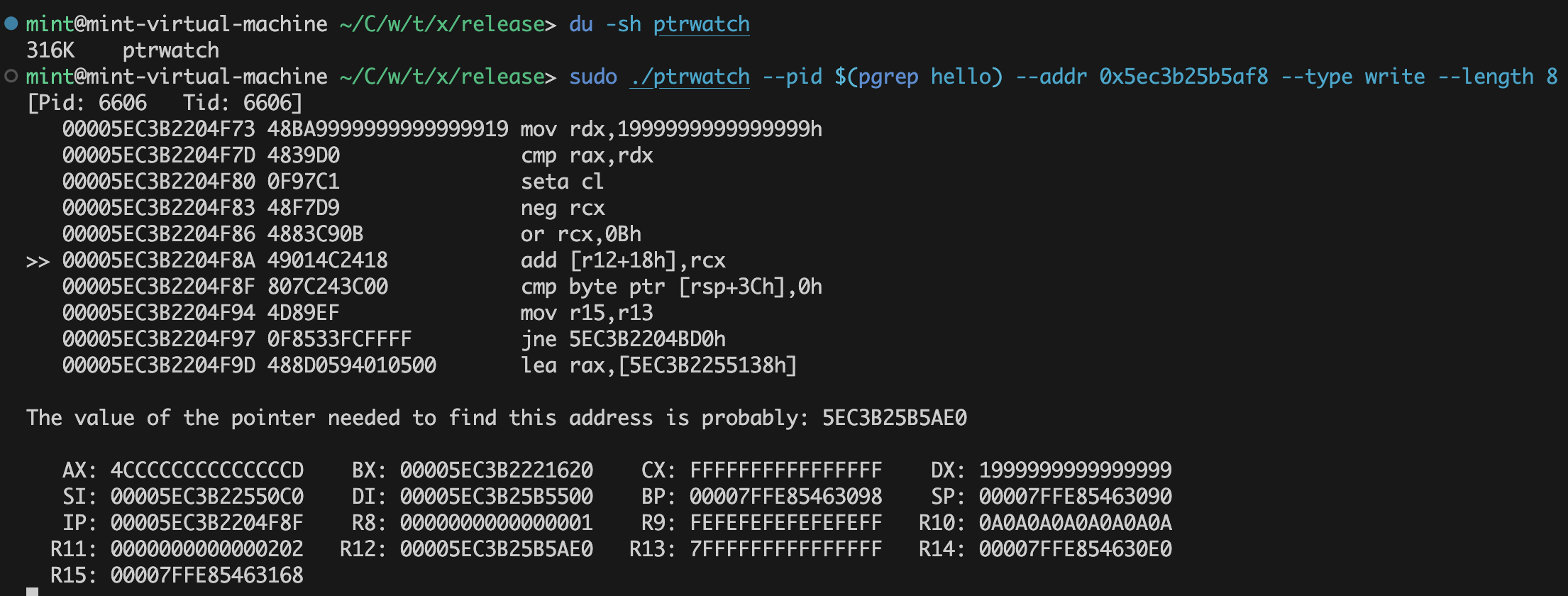
是什么(写入/访问)了这个地址
Contents
前言
这篇文章只是记录我在编写程序时遇到问题的解决过程,文章最下方会放代码链接。
无知就是幸福
最近使用 PINCE 的时候,使用 “找出是什么(写入/读取/访问)了改地址” 功能,由于断点命中次数太多,会造成游戏极其卡顿(从60帧降低到不足10帧),脑抽第一时间以为是Python太慢了造成的。
于是我准备用 Rust 自己实现这个功能。最开始想法非常简单:
-
只需要使用Linux的 ptrace 即可轻松实现断点功能。
-
通过 /proc/pid/maps 查询 IP 寄存器储存的地址所在的内存区域。
-
反编译获取附近指令,猜测内存操作数,再查询对应寄存器储存的数值即可。
但实际上,不知为何,性能非常差劲,依然让游戏卡到几乎没法正常运行。通过互联网上一些相关搜索发现:
- 由于 ptrace 内部是系统调用机制,需要在内核态和用户态切换。当事件数量比较多时,繁忙的切换必然会影响原有服务的性能;
很多人只看到了 ptrace 简单易用,功能还多的好处,却忽略了它对进程性能带来的影响。实际上,我只是需要一个断点,于是发现了 perf。相对于 ptrace 来说,perf trace 基于内核事件,自然要比进程跟踪的性能好很多。使用 perf 还有一个潜在的好处,它目前无法被轻易检测,可以绕过大部分 AC (反作弊)。
重置一切
使用 perf 重新实现断点功能非常容易,我不想解释太多,总之,现在我又遇到了其它问题。现在我的程序虽然对游戏性能 几乎/完全 没有肉眼可见的性能影响,但依然有需要优化的地方,例如:
1. 缓慢的反汇编。
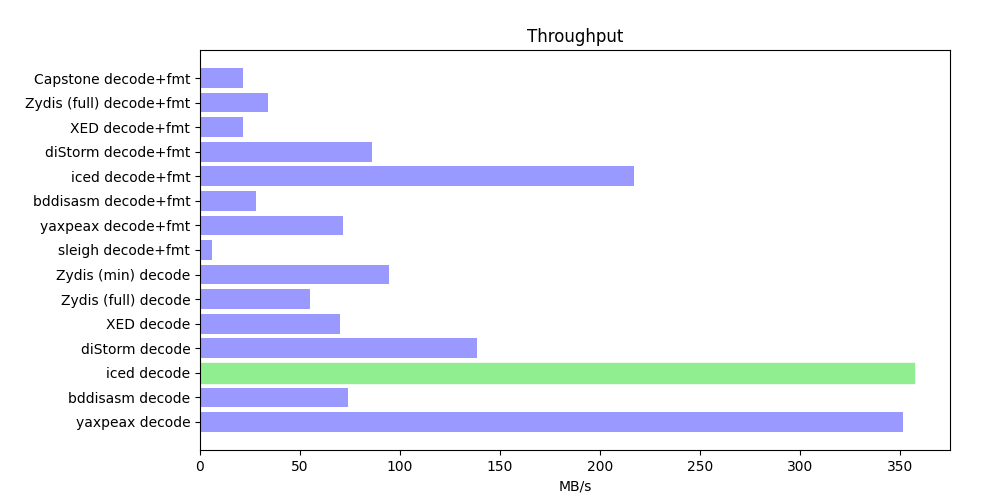
没错,我使用的就是这个几乎性能最差,但是业界使用量最大的 Capstone 完成了我需要的功能。这导致我需要数秒的时间才能获取到一个断点的数据,然而实际上我的断点每秒可能命中几十数百上千次。它的性能让我几乎没法用。
于是使用了看起来性能最好的 Iced 重构代码,幸运的是,Iced 不仅非常成熟而且性能非常好,使用它后获得了极大的性能改善。不过,后来我发现实际上我只是需要 IP 附近的几百个字节,使用 Capstone 还是 Iced 根本没有体感上的性能差距,但快一些总是好的。
Yaxpeax 虽然也很快,但是看起来成熟度远远不如 Capstone/Iced,所以没有尝试。
以下是提到的几个反汇编库的链接
Capstone: https://github.com/capstone-engine/capstone
Iced: https://github.com/icedland/iced
Yaxpeax: https://github.com/iximeow/yaxpeax-x86
2. 获取内存操作的寄存器地址
最开始我甚至想字节解析反汇编的字符串,其中 [] 中间就是内存操作寄存器的名字。但是实际上只需要遍历操作计数然后获取寄存器类型,如果是内存类型,就可以直接查询断点数据获取地址。
3. 实现只读断点

根据 intel 官方手册所说,x86_64 硬件根本不支持只读断点。但是有一种围魏救赵的办法,可以假装支持只读断点。
办法也非常简单,因为 x86_64 支持设置 写入/读写 断点,所以只需要同时使用两个断点的数据,即使用写入的数据,去过滤读写中的写,即可实现只读断点功能。
最终效果
Author kk
LastMod 2024-09-14